
5 Ways to Measure the Impact of Crawled Web Data on Your Business

The analysis you provide is only as good as the raw data you start with. Although data from the open web is often perceived as a commodity, not all crawled data is created equal. Whether you’re relying on a proprietary crawling technology, tapping into a vendor’s firehose, or implementing a combination of both strategies – you must be able to manage data acquisition efforts by measuring both quality and effectiveness of data.
1. Coverage
For all intents and purposes, the open web is effectively infinite. Regardless of the resources you funnel to data acquisition, storage and latency constraints mean perfect coverage is unrealistic. The question then becomes how much coverage is good enough, and how you can improve it incrementally over time. Very often data operations build on several sources (including both internal resources and those provided by vendors) for both redundancy and increased coverage.
2. Granularity
Although coverage is an important foundation, granularity of data can make a dramatic difference in your final product. In information science, the DIKW hierarchy model offers four layers of information types – data, information, knowledge, and wisdom.
Let’s assume it’s your job to provide analysis based on usable web data. Your expertise is to deliver knowledge and wisdom based on raw data. The more granular the information you start with, the easier it is to refine it into usable knowledge and wisdom.
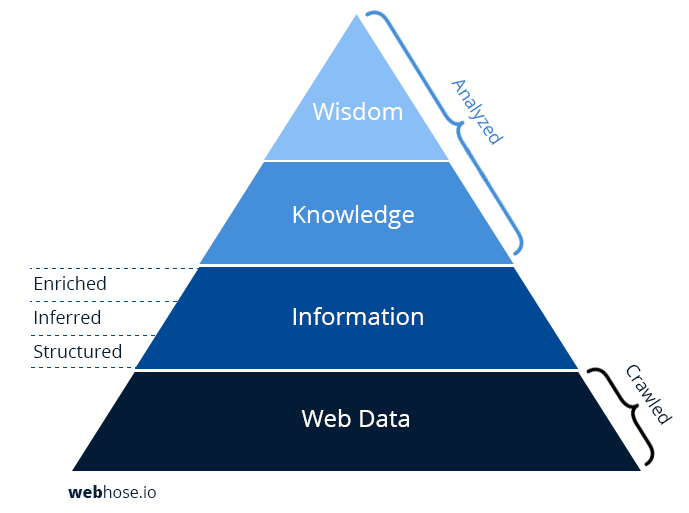
The first layer of granularity is to extract structured information as a machine readable format. This could mean parsing HTML and text into a data structure that includes key fields such as URL, title, or body text. These are relatively trivial as they are clearly marked up in most web pages.
Adding inferred information requires more computing resources. Rudimentary language dependent information falls into this category – the language of a particular web page or associated country (combination of TLD and language). Other types of inferred information include author or element identification such as image or video content.
A final layer of enriched information requires even more processing power; a good example is the ability to identify keywords within a web page as names. Does the word “apple” on a given page refer to the fruit or the computer company? Does my query for “Paris Hilton” refer to a Parisian hotel or to a celebrity? You might even enrich this information higher up the pyramid towards knowledge to understand if this reference includes a positive or negative sentiment. The more granular the data you start with, the easier it is to filter as you move up the pyramid towards analysis.
Learn how to filter crawled and structured web data with Webz.io
3. Latency
Even if your coverage is superb and includes the finest level of granular detail, a third important dimension is time or in this case update frequency. Without it you lose relevance and context. That means refreshing your data at regular intervals to ensure it includes the most current results. Much like coverage, latency is a function of resources. Together, coverage, granularity, and latency determine the quality of your data.
4. Scalability
This measure provides an additional layer to assess your data operation. How easy is it to increase coverage and granularity based on changing needs? Suppose your customer really needs to know the minute a recently published Icelandic blog is updated. Since latency tends to be a function of frequency of publication, including particular blog in the frequently updated bucket requires special attention. How soon can you expand your coverage to include it? Does tweaking your language processing functionality to offer a language spoken by a population of less than a million make sense given budget constraints?
5. Cost of data acquisition
What resources (budget, people, time) are required to provide your customers with the data they need? If your core competence is to deliver quality analysis and insights, your resources can’t be tied to an increasing demand for coverage, granularity, and latency. Ask yourself what is the true cost of your data acquisition efforts, and how you can provide a quality product without losing focus. Sometimes it comes down to a tough business decision – should you build your own crawling solution or rely on a vendor (AKA the build or buy dilemma).
Although measuring both quality and effectiveness of data is critical to success, it remains a challenge. Discover how Webz.io crawls the open web to provide enterprise class data acquisition.




